
The majority of market makers for financial products face very stiff competition to provide prices to their clients. Those who can provide their prices quickest to the market always get an edge on the competition, however, to provide an executable price to their clients, complex calculations are required in the background. Gathering all the input data necessary for these calculations tends to be time consuming and therefore financial institutions are always striving to improve their IT systems, both in terms of design and level of technology. As an alternative, they may choose to build a new system where the data for these computations is held in the memory, namely the cache. Increasing the data held in the cache enables faster access to the input data for the calculations. As a result, they are able to the put their prices to the market quicker.
Over the years, the cost of hardware has plummeted whilst network speed has rapidly increased, allowing financial institutions to take advantage by load-balancing these computations across multiple physical servers. These individual servers may create a local cache of their own, though this itself creates numerous problems, such as maintaining the same version of the data so that different servers produce consistent results. This data includes static data, for example default spreads for counterparty, which can also change. This requires that a single cache must be maintained between multiple physical servers i.e. a distributed cache.
Large multi-national banks generally choose to locate their servers closer to their customers across different geographical locations (e.g. Tokyo, London, New York) thereby reducing network-related latencies over long-distance communications. Accordingly, distributed caching is required to maintain data across various geographical locations.
This poses a new technical challenge for implementing the distributed cache that permits these servers to maintain the same set of data to produce consistent results regardless of which server has calculated it and their geographical location. This is particularly challenging for the servers which must be kept live and up-to-date continuously, instead of periodic refreshing. Examples of such instances include institutions providing OTC products e.g. FX where the market may be opened on Monday morning at Tokyo time and only close on Friday evening at New York time.
Many institutions have built their own proprietary distributed caching solutions. There are also many software vendors who have built products specifically to meet this requirement which are capable of maintaining the distributed cache across multiple server instances (which may be located across different time zones). Examples of these third party products are as follows:
• Hazelcast
• Terracotta / EHCache
• Infinispan
• Oracle Coherence
All of the above providers support more or less the same functionalities, however, for the purpose of this article we will use Hazelcast as an example:
Hazelcast is an in-memory data grid implemented using java libraries, offering implementation of many of the standard java interfaces (e.g. Map, Set, List, and Queue etc.) for supporting the distributed cache. This makes it much easier for the IT teams of these institutions to implement and integrate the distributed caching strategies within their existing systems. In short, if a data element is changed by one Java Virtual Machine (JVM), it is immediately replicated to other servers which belong to the same cluster.
In order to appreciate the challenges, it’s important to understand the terminology used in the Hazelcast distributed caching solutions.
Nodes and Clusters
Nodes are the servers (JVMs) which actively manage the data. A cluster is simply a logical collection of these nodes. A node can join an existing cluster, or if no cluster is available, it starts a new cluster. When a new node joins an existing cluster, the data in that existing cluster is re-partitioned so that ownership of some of the data is transferred to this new node. For this data, the new node is now the primary owner and responsible for all data maintenance activities, such as backup, persistence, change notifications and locking. By default, a copy of that same data is also held in two other nodes of the same cluster. The primary owner node ensures that the other node’s data is kept up-to-date when changed. This means that if the primary node dies, the data is available on the two other nodes, and the cluster is able to recover the data without going back to the database. One of those nodes then becomes the primary owner, and the copy is maintained in another two nodes if available. As a result there is no single-point-of failure.
Replication vs Distribution
Hazelcast is, by default, a distributed cache (as opposed to a replicated cache). This means that only one node is the primary owner of the data. Other nodes may hold this data, but only in their backup area. However, with suitable settings, all other nodes may be configured to hold a copy of the same data in their backup for faster access. This, effectively, makes the cluster behave like a replicated cache.
However, in a truly replicated cache all nodes hold the data and are primary owners. Hence all nodes are responsible for persistence, change notification to other nodes etc.
An advantage of a distributed cache is that it is possible to hold a huge amount of data in the memory of the cluster, with each node holding only a fraction of the whole data set. For example, if we have 10GB of data and a 10-node cluster, then each of the nodes can hold only 1GB of data in their primary area and 2GB in their backup area, meaning that 3GB of physical memory is sufficient for each node in the cluster. If you have a really large amount of data, it is possible to load whole sets of data by increasing the number of nodes. For a replicated cache, since all nodes hold all data, each of the nodes will require 10GB of memory.
Client Nodes
These are the nodes which join the cluster, but do not have ownership of any of the data. They delegate all activities to the owner nodes. However, they have a very powerful feature – , Near-Cache, which enables them to maintain a local copy of any data accessed earlier. The primary node from the cluster is also responsible for maintaining these local copies.
Persistence
The distributed data structures (e.g. Hazelcast Map) may be backed by persistence (e.g. Sybase, Oracle tables or any other entities). In addition, both write-through and write-behind operations are supported. In a write-through operation, any change to the data (e.g. put/remove into Map) is in sync with the database operation. On the other hand, in a write-behind operation, the transaction returns successfully as long as it has written to the backup area of other cluster nodes. The primary node, at a later time, will then collect all the ‘dirty’ entries and make the necessary database changes. All persistence is done using an interface: StoreMap in the case of Hazelcast, which depending on the requirement, can be implemented for any other data source such as Sybase or Oracle.
A hypothetical example
In the following hypothetical situation (see the figure below), we are creating a cluster consisting of three zones (Tokyo, London and New York). In each zone there may be several physical servers connected to the cluster. Any changes to the data by any one server is replicated to the other servers which can be located in the same or other zones.
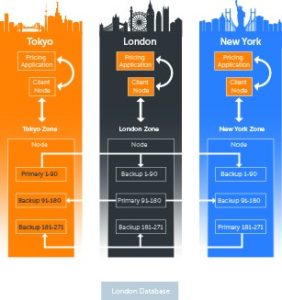
The database server is located in London. Each server node in each of the different zones can access the database directly. It is possible to create mirrored database servers across all three zones, although this is not required here.
Clients may only connect to the servers located in their local zone. For example, a New York-based client will connect to New York Zone nodes only. This will eliminate any Wide Area Network- (WAN) related latency. Moreover, clients will also join the clusters as a Client-Node, utilizing the Near-Cache for its local data preventing unnecessary Local Area Network (LAN) traffic (which may further result in database calls).
As shown in the above figure, the data is channeled centrally into one place: Sybase. Nevertheless, this data is also available locally in the cache at each of the servers in all zones meaning that the data can be accessed more quickly. This data may then be used by the client to compute the price. Since the access is local, retrieval time is almost near zero and similar to retrieving from a HashMap.
Conclusion
In banking, the urgent need for ultra-low latency often conflicts with the large quantities of data that are required. Hazelcast provides an interesting solution to this challenge. With Hazelcast, many of the data structures or implementations are already familiar to the IT developers. Essentially, the IT team of any financial institution can use Hazelcast or any equivalent software to implement their distributed caching strategy to achieve a very low or ultra-low latency for their critical applications.